
前言
最近登录Xshell通过docker ps -a检查容器的运行状态,发现trilium容器状态都是1分钟以前;连续打印状态,我发现每隔十来秒root-trilium-cn-1服务就会被重启一次,难怪最近感觉访问web端有点问题。
为了查到问题原因,于是我向AI发起了决斗🤣。
什么原因造成容器无限重启?
用下面的指令检查进程后发给AI,AI回复显示进程一切正常。
sudo ps -eo pid,ppid,user,%cpu,%mem,vsz,rss,stat,start_time,time,comm:20,args 用docker logs -f root-trilium-cn-1检查trilium日志(大概如下),喂给AI。
root@racknerd:~# docker logs -f root-trilium-cn-1
DB size: 853618 KB
{
"appVersion": "0.63.7",
"dbVersion": 228,
"nodeVersion": "v18.18.2",
"syncVersion": 32,
"buildDate": "2024-05-30T06:59:06+02:00",
"buildRevision": "95d46b7ce7e0036eeb72b43e1815cc5c00dc214c",
"dataDirectory": "/root/trilium-data",
"clipperProtocolVersion": "1.0",
"utcDateTime": "2026-01-03T10:48:38.718Z"
}
CPU model: Intel(R) Xeon(R) CPU E5-2699 v4 @ 2.20GHz, logical cores: 1 freq: 2199 Mhz
Trusted reverse proxy: false
App HTTP server starting up at port 8080
Listening on port 8080
Becca (note cache) load took 62ms
<--- JS stacktrace --->
FATAL ERROR: Reached heap limit Allocation failed - JavaScript heap out of memory
DB size: 853618 KB
AI回复:日志已经明确:Trilium 在启动阶段就 JavaScript heap out of memory,导致容器无限重启。
根本原因:默认 Node 堆上限(≈1.4 GB)无法容纳 853 MB 数据库 + 索引/缓存,单核 1 G 物理机直接爆掉。
目前,宿主机只有 1 G 物理内存,没法增加,数据库也不好精简,如何处理?
Node 堆上限(--max-old-space-size)只能设成 ≤ 物理内存 × 0.75,否则进程一启动就会触发系统 OOM-killer。
在“物理内存 1 GB 固定、假设数据库膨胀到 2 GB 都无法瘦身”这两条硬约束下,不可能让 Trilium 直接把整个库加载进 Node 堆。唯一出路是把数据库搬出内存,让 Trilium 只保留“热数据”。
目标:在 1 GB 内存 的 Ubuntu 服务器上,让 2 GB 的 Trilium 数据库 跑起来,不崩、不 OOM。
那么,在「不能加内存」的死命令下,任何方案都必须让“工作集”< 700 MB,Docker 需要把多余内存换到 swap,因为一旦 RSS 超过 900 MB 就会直接被 OOM-killer 干掉。
📦让内核开启 swap account(需要一次重启)
# 1. 修改 grub,执行下方指令,打开grub
sudo nano /etc/default/grub找到 GRUB_CMDLINE_LINUX="net.*" 这一行,替换下面这段,改成下图这样:
GRUB_CMDLINE_LINUX="net.ifnames=0 biosdevname=0 netcfg/do_not_use_netplan=true cgroup_enable=memory swapaccount=1"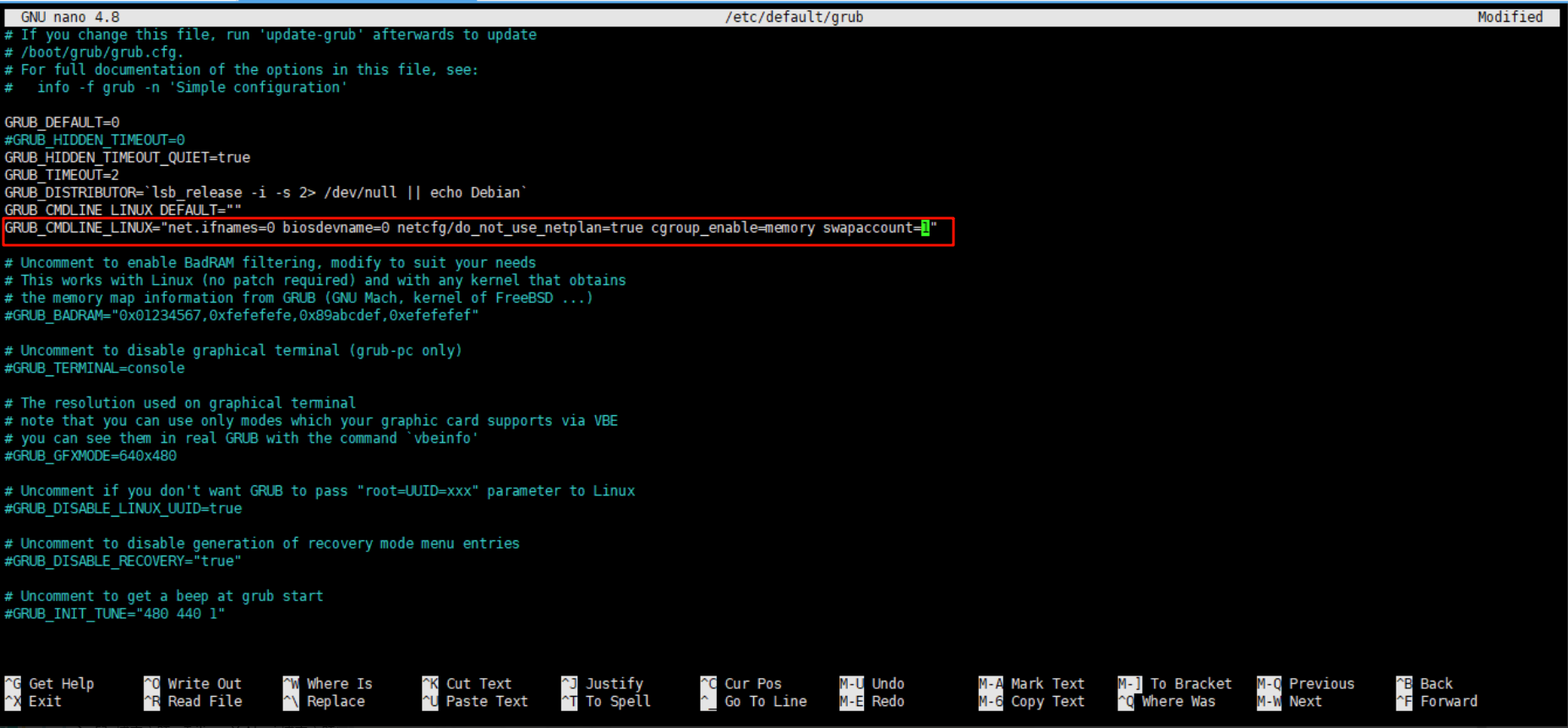
- 在 nano 里,改好内容后按
Ctrl + O → 出现文件名提示 → 直接回车(保存)
- 再按
Ctrl + X → 退出 nano
若你觉得nano操作不方便,可以到服务器路径/etc/default/grub,编辑grub文件,方法同上。
# 2. 更新,重启
然后一次性执行:
sudo update-grub
sudo reboot就完成了。
👉建 3 GB swap(一次性),让1 GB 物理机也能拖动 2 GB 库。
sudo fallocate -l 3G /swapfile && sudo chmod 600 /swapfile && sudo mkswap /swapfile && sudo swapon /swapfile
echo "/swapfile none swap sw 0 0" | sudo tee -a /etc/fstab⚙️修改trilium的相关的docker-compose.yml(到你原来的存放路径下替换下方代码)
version: '3'
services:
trilium-cn:
image: nriver/trilium-cn
restart: always
ports:
- "8080:8080"
volumes:
- ./trilium-data:/root/trilium-data
environment:
- TRILIUM_DATA_DIR=/root/trilium-data
- NODE_OPTIONS=--max-old-space-size=720
mem_limit: 900m
memswap_limit: 3g
# 可选健康检查(需要宿主机有 curl 和 jq再打开)
#healthcheck:
# test: ["CMD-SHELL", "curl --fail http://localhost:8080/api/health-check | jq -e '.status == \"ok\"' || exit 1"]
# interval: 30s
# timeout: 10s
# retries: 3相较于源yml只增加了如下内容:
# ① 关键:把 Node 堆上限压到 720 MB(留 200 MB 给系统/SQLite/page-cache)
- NODE_OPTIONS=--max-old-space-size=720
# ② 关键:容器最多吃 900 MB(含 RAM+swap),防止触发宿主机 OOM
mem_limit: 900m
memswap_limit: 3g # 允许再用 2.1 GB swap🎯进入到trilium的docker-compose.yml路径,重启容器
docker compose down # 停旧容器
docker compose up -d # 启动新配置✅观察
docker compose logs -fdocker ps -a观察同步的时候,不再出现 FATAL ERROR: Reached heap limit 就成功;
不再出现trilium容器状态频繁刷新就成功;
浏览器访问 http://<IP>:8080 能打开即完工。


